AI 필기장 - 3. 트랜스포머
트랜스포머
포지셔널 인코딩
기존 seq2seq는 RNN or LSTM 기반이기 때문에 단어를 순차적으로 받아 단어의 순서를 신경쓰지 않아도 됐다.
하지만 트랜스포머는 Incoder와 Decoder로만 구성되어 있기 때문에 입력받은 단어의 순서를 모른다.
따라서 각 단어별로 임베딩을 한 뒤, 임베딩 벡터들에 순서 정보를 입력해주는 포지셔널 인코딩을 수행한다.
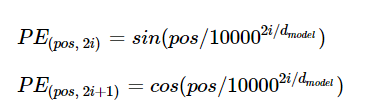
위 식에 따라 임베딩 벡터에 더해주면 입력값의 순서 정보가 벡터에 저장되게 된다.(더한다 = 의미 정보를 추가한다.)
식을 보면 인덱스가 짝수일 경우는 사인 함수, 홀수일 경우는 코사인 함수를 사용한다.
"I like car but I don't like animal"
위 문장에서 컴퓨터는 앞의 like와 뒤의 like를 구분하지 못하지만, 포지셔널 인코딩을 통해 앞의 like는 car와 관련되어 있고 뒤의 like는 animal과 관련되어 있다는 걸 알게 된다.
- 포지셔널 인코딩의 장점
- 모든 인코딩 값은 -1~1의 값을 가진다.
- 학습 데이터 중 가장 긴 문장보다 더 긴 문장이 들어와도 오류없이 인코딩이 된다.
셀프 어텐션
기존 어텐션 seq2seq는 매 t시점마다 연산을 해야 했다.
- 첫 단어를 예측한다.
- 예측한 단어에 따라 인코더의 어텐션 가중치를 새로 계산해 다음 단어를 예측한다.
- 1번부터 반복
셀프 어텐션은 이렇게 매번 인코더의 어텐션 가중치를 계산하기보다, 아예 처음부터 각각의 가중치 값을 모두 계산해 가지고 있다가 디코딩 시에 그 가중치 행렬을 계산해주기만 한다.
Query, Key, Value 에 해당하는 가중치 행렬을 새롭게 만들어 단어 임베딩 벡터에 행렬곱한다. -> 각 단어마다 Query, Key, Value 벡터가 생성된다. Query = 현재 단어 SoftMax(Query * Key) = 현재 단어와 Key 단어가 얼마나 연관되어 있는지 나타낸다.
Query 벡터 * Key 벡터
I * I = 0.92
I * study = 0.05
I * at = 0.01
위 결과 값에 Value 벡터를 곱해주면 연관성이 없는 Value값들은 값이 매우 작아지게 된다.
-> Value 값들을 모두 더해주면(가중합) 의미있는(다음 예측을 위한 힌트가 되는) 최종 Value 벡터가 나온다.
디코더는 현재 단어를 Query로 하여 인코더의 Key, Value에게 물어본다.

댓글
댓글 쓰기