AI 필기장 - 2. 자연어 처리
Word2Vec 속도 개선
만약 CBOW 모델에서 입력값이 어마어마하게 많아지면 -> 앞 쪽과 뒤 쪽에 병목구간이 생긴다.
앞 쪽 Embedding 계층 : 계산할 필요없이 해당 단어의 행을 뽑아냄.(시간 단축) 역전파할 때 기울기값을 더한다.(대입을 해버리면 앞의 계산을 무시함 - 인덱스 중복되는 행을 가르키고 있을 때)
뒤 쪽 Negative Sampling : MatMul(?)과 SoftMax 계산의 연산 수를 줄여야 한다. -> 다중 분류를 이중 분류로 바꿈(예 아니오 문제로)
= Softmax(x) Sigmoid(o)
SoftMax를 사용했을 땐 정답 레이블이 필요 없었다 -> Sigmoid를 사용하면 정답 레이블을 추가해줘야 하나?(데이터 셋 추가?)
= 맥락에 따라 정답이 정해져 있기 때문에 정답 레이블을 계산할 수 있다. 네거티브 샘플링 시 정답을 제외한 단어 중 무작위로 추출한다.
하지만 yes 일 경우만 생각했기 때문에 no 인 경우에 분류가 안된다.
So 몇 가지의 부정적인 경우를 뽑아내 동일하게 학습시킨다.
Word2Vec 를 활용하여 여러 가지 딥러닝에 사용할 수 있다.
RNN(Recurrent Neural Network) - 순환 신경망
기존의 피드포워드(Feed Forward) 신경망은 단순히 앞 계층의 신호를 다음 계층으로 전달하기만 해 시계열 데이터를 분석하기 힘들다.
시계열 데이터 : 시간의 흐름에 따라 나타나는 데이터로, 과거의 데이터를 분석하여 미래의 결과값을 예측하는데 쓰인다.
ex) 주가, 날씨, 판매량 예측
언어 모델
단어의 나열에 확률을 부여한다. 따라서 단어들의 확률값에 따라 자연스러운 문장인지 구별할 수도 있고,
다음에 자연스럽게 나타날 단어를 예측하여 생성할 수도 있게 해준다.
아래 확률의 곱셈 정리를 이용해 문장 내 단어들의 동시 출현 확률을 수식으로 나타낼 수 있다.
확률의 곱셈 정리
P(A,B) = P(A|B)P(B)
즉, A와 B가 모두 일어날 확률 P(A,B) 는 B가 일어날 확률 P(B) 와 B가 일어난 후 A가 일어날 확률 P(A|B) 의 곱이다.
동시 출현 확률의 수식은 다음과 같다.
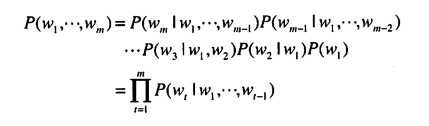
위 수식의 결과는 t번째 단어의 왼쪽에 있는 모든 단어를 맥락으로 고려했을 때 t번째 단어가 나타날 확률이다. 따라서 위 확률을 계산한다면(모든 경우의 수를 계산한다면? - 현실적으로 불가능하다) 언어 모델의 동시 확률을 구할 수 있다.
RNN 계층 구조
피드포워드 방식의 신경망은 여러 개의 계층을 가져 서로 입력과 출력을 주고 받지만, 기본적인 순환 신경망에선
단 하나의 계층만이 존재하고, 현재 입력 + 이전 출력 을 계속 계산해간다.
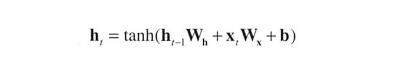
h(t) : 현재 출력해야 하는 값
h(t-1)W(h) : 이전 출력
x(t)W(x) : 현재 입력
b : 편향
BPTT(Backpropagation Through Time) 역전파 시에 너무 깊어지면 0값이 되어버린다(Vanishing Effect) -> Truncated BPTT : 너무 깊게 들어가지 않고(너무 많이 예상하지 않고) 중간에 짜른다.
시계열 데이터에선 데이터의 연속성이 매우 중요하기 때문에 순서를 항상 고려해야 한다.
미니배치를 적용할 때 만약 1000개의 데이터를 2개의 미니배치로 자른다면 0~499 의 데이터를 먼저 학습하고,
500~1000 의 데이터를 학습할 수 있게 OFFSET을 옮겨 주어야 한다.
RNN 모델에서 역전파 시 결과 기울기 값과 미래의 기울기 값 두 개가 나오기 때문에 더해주어야 한다.
RNNLM(RNN Language Model) RNN 모델을 언어 용으로 만든 모델 TimeRNN(??)
perplexity : 확률의 역수, 나올 확률이 적을 수록 값이 커진다.(작을 수록 좋은 모델)
ex) 8개 중 1개를 고른다 -> 확률 = 1/8, perplexity = 8, 8가지를 고를 수 있다.
Time RNN은 다른 모델과 다르게 데이터의 연속성 때문에 처음부터 끝까지 배치 데이터를 연속적으로 짤라야한다.
RNN의 문제점 - 기울기 소실과 기울기 폭발
RNN의 계층은 '+', 행렬곱, tanh 연산 총 세 개의 연산으로 구성되어 있다.
역전파 시에 '+'는 기울기를 그대로 전달하지만, 행렬곱과 tanh 연산은 그렇지 않은데,
이 때문에 기울기 소실, 기울기 폭발 문제가 발생한다.
tanh 연산(기울기 소실) tanh 함수의 미분 함수는 1 - y^2 으로, 그래프로 그려보면 아래 그림과 같다.
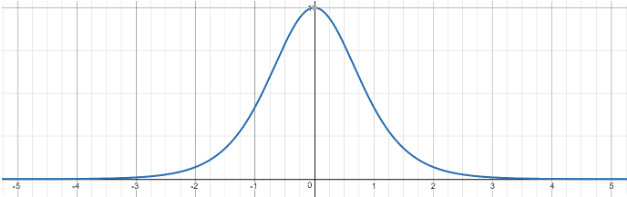
즉, x가 0으로부터 멀어질수록 기울기 값을 작아지는 것을 볼 수 있다. tanh 함수를 많이 거칠수록 기울기는 작아지게 되는 것이다.
이러한 기울기 소실 문제는 ReLu 함수를 사용하여 해결할 수 있다.(ReLu 함수는 x가 0보다 클 때 단순히 기울기를 그대로 전달한다)
행렬곱 연산(기울기 소실, 기울기 폭발)
A라는 스칼라 값이 있다고 하면, A를 여러 번 곱했을 때 A가 1보다 크다면 증가할 것이고 작다면 감소할 것이다.
스칼라 값은 값이 하나이기 때문에 단순하지만, 행렬은 값이 여러개이기 때문에 행렬의 특잇값 을 기준으로 한다.
행렬의 특잇값 중 최댓값이 1보다 크면 기울기가 증가하고, 작다면 감소하게 된다.(그럴 가능성이 있다.)
LSTM(Long-Short Term Memory)
짚고 넘어갈 점
- 원소 별 곱(아다마르 곱)을 한다는 것은 각 원소마다 중요도를 부여하는 것. - 해당 원소를 삭제할수도 있다.
- 원소 별 합을 한다는 것은 내용을 그저 추가한다는 것.
- tanh 함수는 -1~1 사이의 값을 가진다. = 정보의 중요도를 나타낸다고 볼 수 있다.
- sigmoid 함수는 0~1 사이의 값을 가진다. = 0~100% 중 얼마나 통과시킬 지를 나타낸다고 볼 수 있다.
LSTM에는 기억 셀(memory cell)이 추가된다. 이 기억 셀은 여러 시각(t) 를 거치면서(게이트들) 옛날의 정보를 잊지 않고
기억하고 있다. 옛 정보를 기억하고 있다가 입력값(h)와 연산을 하여 더 좋은 출력을 얻게 도와준다.
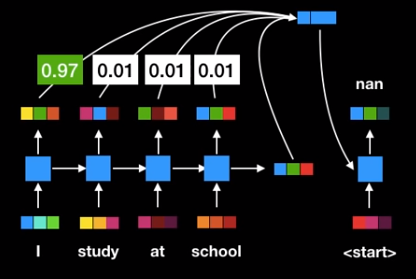
문장 생성
결정적 선택 : 확률이 가장 높은 것이 선택된다. 확률적 선택 : 각각의 확률에 맞게 랜덤하게 선택된다.(확률이 작아도 선택될 수 있다.)
문장 생성의 기본 아이디어
- 언어 모델에서 확률적 선택에 의해 단어가 추출된다.
- 추출된 단어를 다시 언어 모델에 넣는다.
- 1번을 계속 반복한다.
seq2seq
seq2seq는 언어 번역에서 많이 사용되는 모델이다.
이 모델은 하나의 Encoder와 하나의 Decoder로 구성되어 있다.
Encoder에 어떤 문장을 넣으면 Encoder의 학습된 언어 모델에 의해(여러 복잡한 계산을 거쳐) 원래 문장의 정보를 담고 있는
하나의 고정 길이 벡터가 생성된다.
Decoder는 이 고정 길이 벡터의 정보를 바탕으로 새로운 문장(번역된)을 만들어간다.(위 문장 생성 과정)
고정 길이 벡터 : 언어 모델에 의해 계산된 값으로, 사람은 이해할 수 없고 다만 Decoder에게 넘겨주면 의미 있는 정보를 내보낸다.
seq2seq의 개선
- 데이터 반전 : "This is a car"라는 문장은 "이것 은 자동차 이다"로 번역될 수 있다. 가장 먼저 번역되는 "이것" 에 해당되는
"This"는 가장 먼저 인코딩된다. 즉, "This"와 "이것"의 거리가 길어 의미를 잃어버릴 수 있다(까먹을 수 있다)는 것이다.
"car a is This"처럼 입력 데이터를 반전시켜 학습한다면 "This"와 "이것"의 거리가 가까워져 정확도를 높일 수 있다. - 엿보기(Peeky) : 기존의 seq2seq 모델은 인코딩된 벡터(가장 중요한 정보)를 Decoder의 맨 처음 노드에만 알려줬다.
이 벡터를 Decoder의 모든 노드에게 알려주어 학습시킨다면 정확도를 높일 수 있을 것이다.
(구현 시에 벡터를 단순히 concatenate 하여 추가한다.)
어텐션
얼라인먼트(Alignment) : Cat = 고양이 처럼 단어의 대응 관게를 나타내는 정보로, 어텐션에선 이러한 정보를 seq2seq가 자동으로
학습하도록 만들었다.
어텐션의 매커니즘 : 상태와 상태 간의 관계를 알아내면 더 효율적인 학습이 될 것이다.(예측을 할 때 힌트를 갖고 예측한다.)
seq2seq는 순서 관계에 약하기 때문에 어텐션에서 순서에 상관없는 힌트를 준다.
LSTM에서 나온 h값들을 Decoding 하기 전에 힌트를 받아(여러가지 방식이 존재 - 새로운 신경망 or 내적) 계산을 한다.
기존 seq2seq 모델에선 아래 그림과 같이 인코더에서 은닉 벡터인 고정 길이 벡터(h) 만을 출력으로 내보냈다.
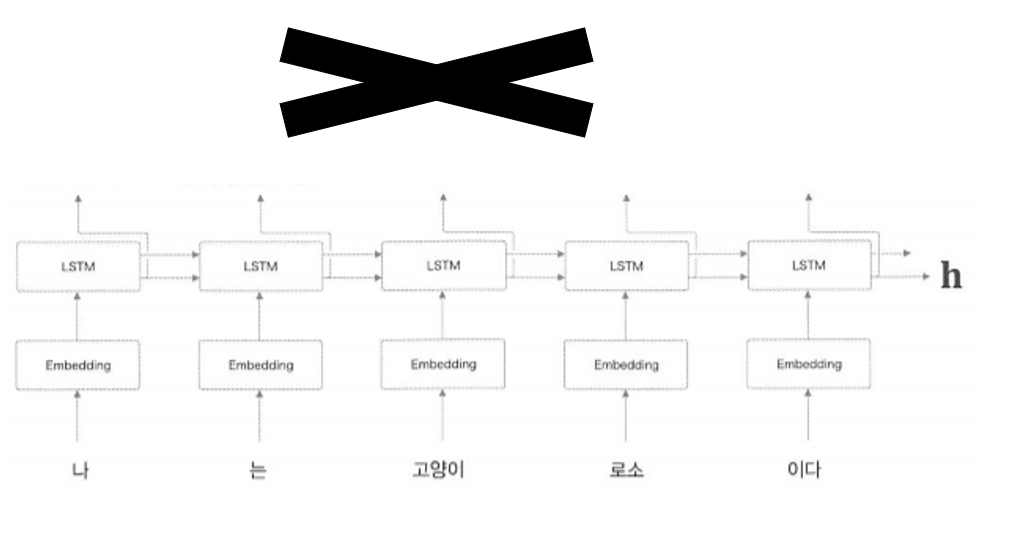
어텐션에선 고정 길이 벡터를 사용하지 않고 인코더의 각 노드에서 나온 값들 + 현재 보고 있는 단어 를 계산해 다음 단어를 예측한다.
WeightSum 계층
가중치 a가 주어지면 가중합을 이용해 어떤 값이 가중치가 높은 지 계산해 위 계층에서 판단할 때 도움을 주는 계층
AttentionWeight 계층
가중치 a를 구해서 WeightSum 계층에 넘겨준다. 가중치 a를 구하는 법 : 단어들을 모은 hs와 비교할 단어 h 를 내적하면 유사도가 구해진다.(코사인 유사도)

댓글
댓글 쓰기